Cropin is releasing its first Micro Language Model (µ-LM) for climate smart agriculture, akṣara, under the Apache 2.0 license, without any restrictions. This removes barriers to knowledge and empowers anyone in the agriculture ecosystem to build frugal and scalable AI solutions for the sector.
The major focus countries are India, Bangladesh, Nepal, Pakistan, and Sri Lanka. The major focus crops are Paddy, Wheat, Maize, Sorghum, Barley, Cotton, Sugarcane, Soybean, and Millets.
This question-answering system is based on the Mistral-7B instruct-tuned model, and akṣara is fine-tuned on a dataset from the above focus countries and crops and then compressed from 16-bit to 4-bit, using QLoRA, for minimal resource consumption during inferencing while still giving ~40% more relevant ROUGE score than GPT-4 Turbo on randomly selected test datasets. The knowledge domain of the model is specific to the agricultural best practices, including climate-smart agricultural practices (CSA) and regenerative agricultural practices (RA) for the above-mentioned focus countries and crops. More geographies and crops will be added later. The model is trained on a database containing information from seed sowing to harvesting, covering every phenological stage of the crop growth cycle and different aspects like crop health management, soil management, disease control, and others. The end-to-end pipeline incorporates various aspects of Responsible AI (RAI), like considering local features and preventing harmful content or misinformation.
Why did we do it?
In Albert Einstein’s words: “You can’t solve a problem on the same level that it was created. You have to rise above it to the next level.” In Agtech, where there’s no precedent, we always start fresh when working on new projects or problems. One challenge we are passionate about solving is the impact of climate risks on agriculture. No matter how many solutions we develop, use cases we explore, or AI models we introduce, the enormity of this problem is such that climate change continues to present new challenges.
We are also convinced that the best solution to mitigate climate change risks in agriculture is empowering every farmer to be climate-smart. However, this is no easy feat. At a time when farmers worldwide face numerous challenges, empowering them with sustainable and climate-smart farming methods is a daunting task. But we firmly believe that a day will come when the world will unite to empower the 600+ million farmers worldwide to mitigate climate risks. Farmers are a powerful force themselves, and without empowering them and transforming global food systems, we will never achieve our net-zero goals.
It is with this conviction that Cropin’s AI Labs team shares this AI-enabled development to empower farmers to be climate-smart, especially those in the global south. We need your support to ensure it reaches every farmer in the global south, as well as agronomists, agri-scientists, researchers, academia, and policymakers.
How did we do it?
Step 1: PoP dataset creation
Cropin has 14 years of experience in this field. We have been providing farmers and other stakeholders with relevant information on agricultural best practices, CSA, and RA for many years now. As part of these advisories, we created various farm management practices or Package of Practices (PoPs), but we had to curate these again as the information might have become stale. We selected 100 PoPs for the earlier mentioned focus countries and crops and further added some more PoPs to take the total to 620 PoPs. Note that each PoP is a set of steps catering to a specific aspect of agriculture for a specific crop in a specific region.
Following is the crop-wise distribution of PoPs in the PoP dataset.
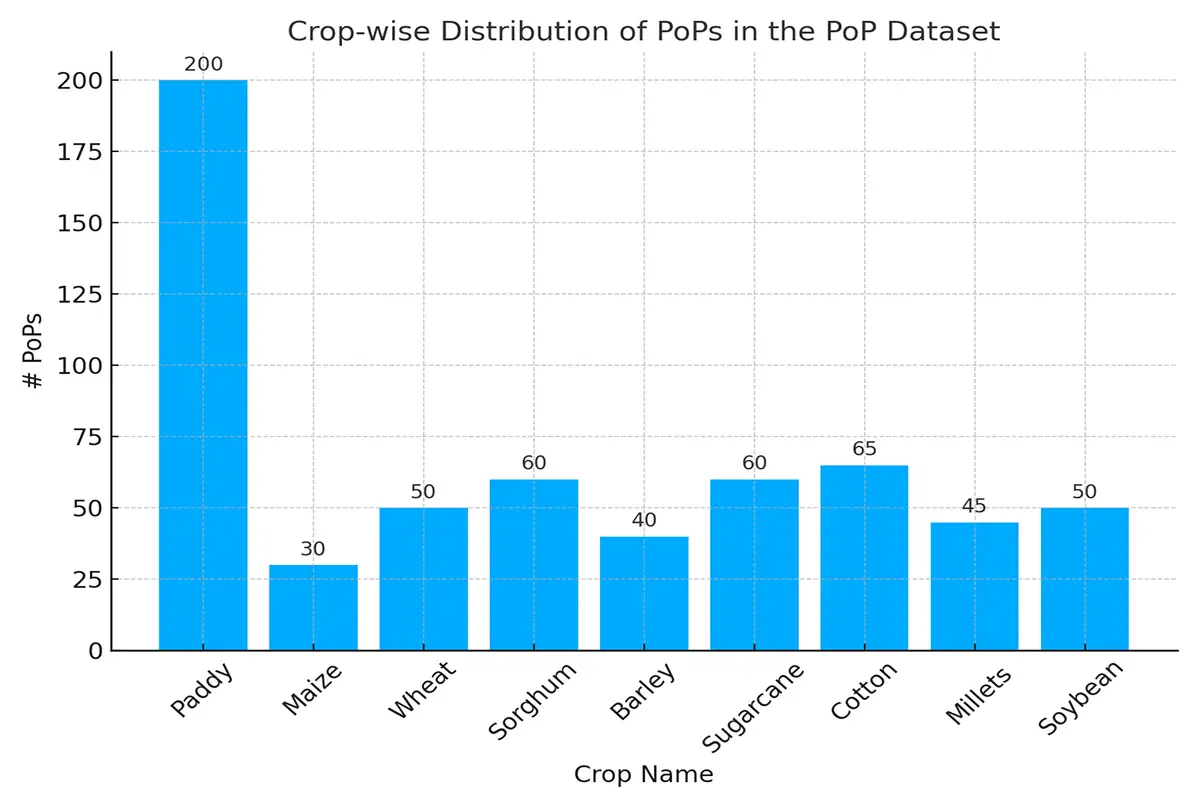
Once the PoPs were finalized, we had to create questions and answers (QnA) using them for instruction fine- tuning. We used GPT-4 Turbo to generate ~5000 questions using these PoPs. PoP refers to good agriculture practices, and 50 PoPs mean 50 different ways of growing a crop in the Indian subcontinent/global south.
These QnA were then manually verified to ensure truthfulness and variation in the data. Wherever we found some quality questions not getting generated, we added them manually to the dataset.
Step 2: Model creation
We built upon Mistral-7B 16-bit, an open-source Large Language Model (LLM) with 7-billion parameters developed and released by MistralAI. For the use case under discussion, we used the Instruct version of the Mistral model. We will call it the ‘base model’ henceforth.
Base model is fine-tuned with QLora on the Instruction tuning dataset for 1 epoch. The rank of adapters is kept at 32. We use the PEFT library from Hugging Face for this fine-tuning.
Finally, the merged model is compressed to 4-bits using NF4 (4-bit Normal Float) Quantization.
We tried some newer Quantization approaches like QALora as well, but it didn’t result in stable training. We will continue exploring quantization, pruning, and other compression techniques as we eventually want to be able to run our model locally, even on resource-constrained devices.
Step 3: Application architecture
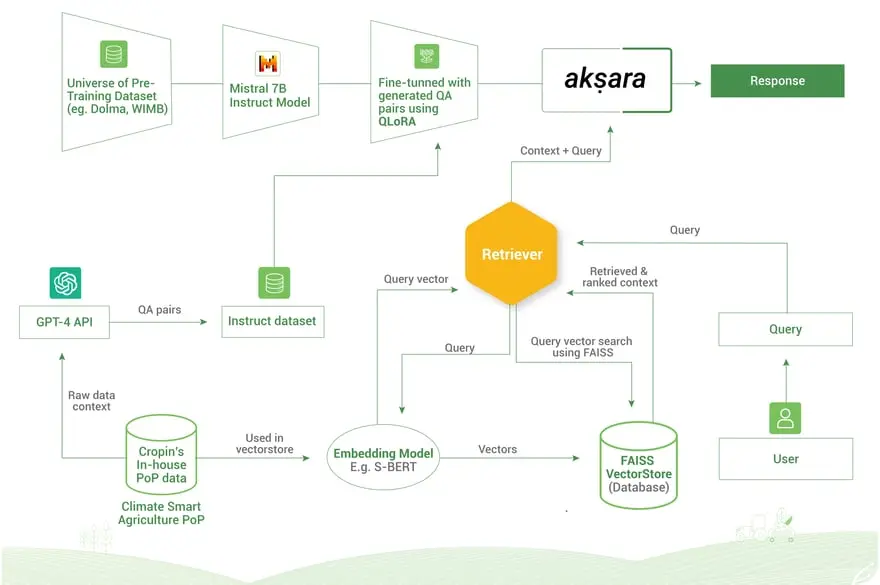
Figure 1: Architecture
As shown in Figure 1 above, our application is based on Retriever Augmented Generation (RAG). We used RAG because while inferencing our initial fine-tuned model, we found that many of the responses were too specific. The responses missed out on generic advice and conversational behavior. There were also instances of hallucination when queries were out of the training data domain. We hypothesize that it was due to two reasons:
- Overfitting was observed with respect to some data points due to unoptimized ‘rank’ and ‘lora_alpha’ hyperparams.
- Compressing the model led to catastrophic forgetting in some cases.
There was another problem: more data was being curated while we were iterating on the model. We didn’t want to keep fine-tuning even if there was only a small change in the dataset. To counter these issues, we implemented RAG using LangChain. Following is the workflow now:
- We embedded all the PoP datasets using S-BERT.
- All of these embeddings were indexed in a FAISS vector database.
- Any incoming query is also embedded using S-BERT.
- Retriever takes this embedded query and finds similar matching documents from the vector store. We keep a minimum similarity threshold of 0.25 and pick up top-4 matches.
- To keep it grounded, these top-4 matching PoPs are passed in as context to our fine-tuned model.
We have many ideas for improving this RAG further. If you have any suggestions or want to collaborate on this, please feel free to contact us (see the ‘How to Contribute’ section).
From an infrastructure point of view, this whole application takes ~6 GB of CPU RAM, ~ 6 GB of GPU RAM (thanks to 4-bit compression) and can run on even 2 CPU cores.
Step 4: Making AI responsible
We all understand that AI systems are probabilistic in nature and can lead to a negative impact on society and the environment if we are not careful. That is why we have taken the following steps to ensure our AI behaves responsibly.
Cropin, as an organization, has always advocated for ways that do not or minimally impact the environment. While giving advisories, we give preferences to biological controls over mechanical and chemical means in order to help preserve beneficial crops, insects, and the entire ecological systems. During the initial testing of our model, we observed that some of the responses did not follow this preference. We reviewed the data again and added any missing information on environmentally friendly practices related to different aspects of agriculture. This will be an ongoing exercise in which we will continue adding relevant data and teaching our model to be more responsible. We are also working on some Alignment techniques, such as Direct Preference Optimization (DPO)9 to improve this aspect further.
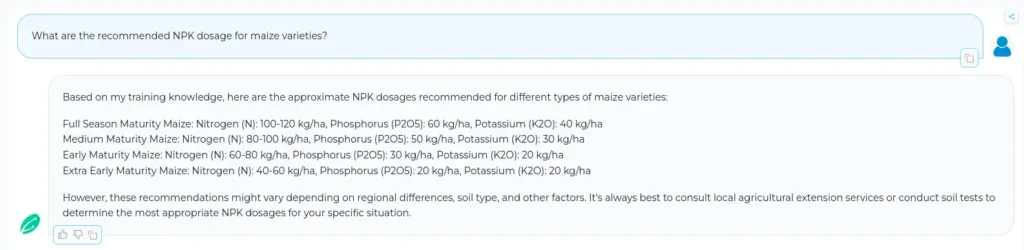
Wherever applicable, we have created the PoPs with exact numerical values for the dosages of chemicals mentioned. This allows our model to give fine-grained answers instead of generic ones given by many other LLMs. This also prevents any harmful action taken by farmers due to over/under dosage. For e.g., as we can see in the following image, akṣara’s output gives precise numbers for the dosage suited according to the stage of the crop.
We believe that the capability of LLMs regarding non-English languages, especially languages prevalent in the Indian sub-continent, is not up to the mark. Hence, we have taken a conscious call to block interaction with akṣara in non-English languages. We do not want any harmful content or misinformation to go out in response because of a lack of language capabilities and instead focus on giving accurate information in English only for now. Our eventual goal is to provide support for these native languages so that we can reach out to the last person. Please check out the ‘How to Contribute’ section and contact us if you want to collaborate on this.
We have trained akṣara to have the persona of an Agronomist. We have added guard rails to avoid answering questions unrelated to agriculture. A separate filter also checks profanity in inputs and blocks such interaction. However, we also understand it’s easier said than done when it comes to LLMs. So, we humbly request you to give us feedback in case you find it breaching in any of your interactions with akṣara. We promise to keep the confidentiality of your feedback and will work to improve the guard rails further.
Results
For the evaluation, we compared our model with the GPT-4 Turbo.
For qualitative analysis, we compared a small number of test outputs from both models with the ground truth. As expected our model provided more factual and numerical data in the response compared to GPT-4 Turbo. For e.g., as shown in Figure 2 below, akṣara’s output for the query ‘How can I control Thrips in my maize crop?’ contains precise values for the chemical treatment of Thrips in Maize. Whereas the output from GPT-4 Turbo shown in Figure 3 does not provide such precise values for chemical control if I ask the same query.
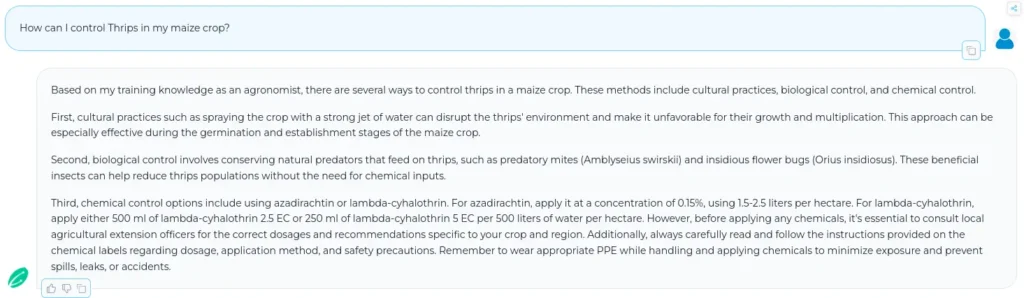
Figure 2: akṣara’s output

Figure 3: GPT-4 Turbo output
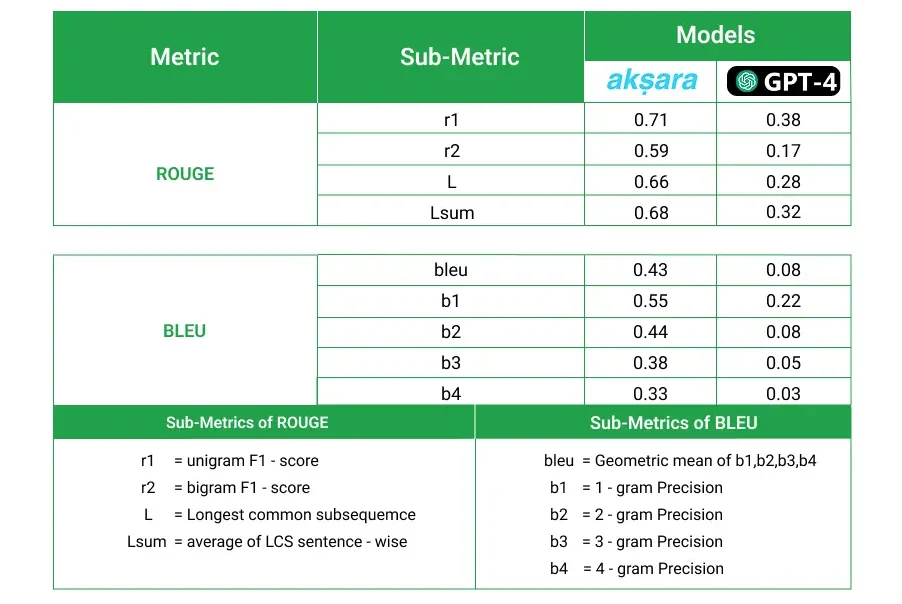
For quantitative analysis, we compared the ROUGE and BLEU scores of akṣara and GPT-4 Turbo with the ground truth as a reference. This was done for the whole test dataset, and as seen in the following table, the outputs from akṣara were closer to the ground truth than those of GPT-4.
We will also release a pre-print with more details on Arxiv very soon.
How to access?
akṣara is accessible via Hugging Face at: https://huggingface.co/spaces/cropinailab/aksara
The app section provides an interactive dashboard to ask questions in English. Note that currently, only select geographies and crops are the focus of the training corpus. So, you may get a bit more generic answers for other geographies and crops.
The files section provides code for the application.
How to contribute?/collaborate
We have lofty goals for akṣara. We want to cut the divide created by language, resources, and literacy and make it possible for every farmer to access this information easily. And while we will pursue this noble mission anyway, more hands and brains can help us expedite the journey. So, we call for enthusiasts to reach out to ‘ailabs@cropin.com’ in case they want to collaborate with us on taking the next steps. If you are a lone wolf and want to build on your own, we are open-sourcing the model and application code (training code will be released soon) to build upon it. We will continue to open-source any new advancements we make in this project.
Acknowledgements
We extend our gratitude to the open-source community, whose diverse contributions form the foundation of akṣara. A special acknowledgment goes to the Mistral team for open-sourcing their model, thus eliminating barriers to accessing high-quality LLMs. We are also grateful to Google’s Responsible AI team for their discussions and access to Google’s People + AI Guidebook, which helped guide the model’s design process.
References
- https://mistral.ai/news/announcing-mistral-7b/
- https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
- https://platform.openai.com/docs/models/gpt-4-turbo-and-gpt-4
- https://huggingface.co/docs/peft/en/index
- https://ai.meta.com/tools/faiss/
- Lewis, Patrick, et al. “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
- Dettmers, T., Pagnoni, A., Holtzman, A. and Zettlemoyer, L., 2024. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
- https://ai.google.dev/responsible
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2305.18290
- https://www.sarvam.ai/blog/announcing-openhathi-series
- https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- https://www.apache.org/licenses/LICENSE-2.0
Disclaimers
- akṣara is still in the beta testing stage. Please verify information from it with agronomy experts or local extension officers
- Responses from the application (like those shown in the snapshots above) are point-in-time outputs. They may change as we are making regular changes in the data, model, and application.